Photo by Federico Beccari on Unsplash
This is the fifth blog post in the “Blockchain for Test Engineers” series.
Blockchain is not a usual distributed system. It is a peer-to-peer network of nodes that communicates with each other.
Today we will have a brief info on what peer-to-peer network is, why it is used in building distributed systems. Additionally, we will take a look at the way how new messages are propagated in the peer-to-peer networks.
The ways how networks can be organized
Client-Server model
This is a very common way for us to organize networks. It is a very familiar model for any test engineer working on WEB or mobile applications.
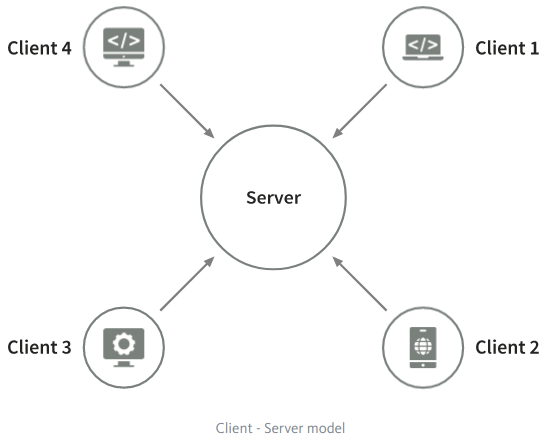
This type of organization allocates one (or more) nodes that have a server role. Other nodes are clients. Clients make requests to the server using various communication protocols (HTTP, RPC, etc). The server processes the request and responds to the client.
Despite of fact, that this way of system organization is a very widespread - it has it’s own problems. The main disadvantage of the model is that the server is somehow the only point of failure. Attackers can either take over the server and access information from customers (thereby interfering with the normal operation of the application). Or - with the help of DDoS attacks - make the server inaccessible to clients.
One way to deal with a single point of failure is to use multiple servers in different parts of the world. This approach works but adds to the difficulty of replicating data between these servers. But about this - another time :).
Peer-to-Peer model
It turns out that you can avoid problems with a single point of failure, even without multiple servers.
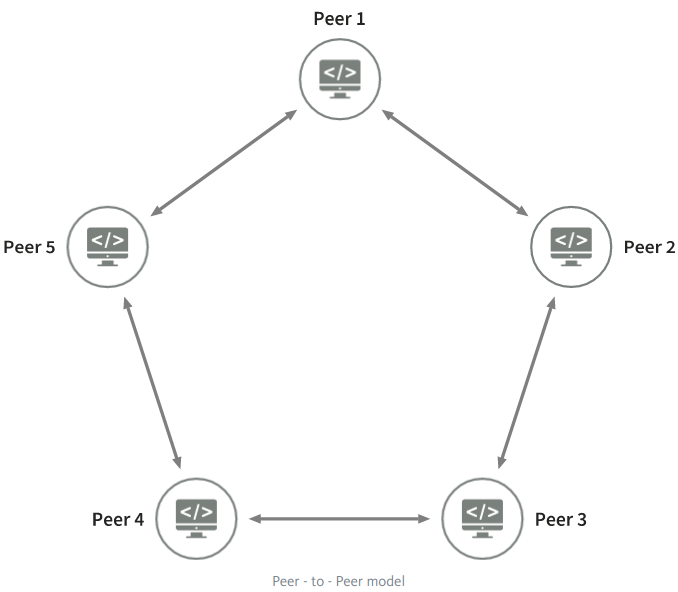
In Peer-to-Peer (P2P) networks, each node (computer) is equal to another (logically). In fact, each node is a server and a client at the same time.
Each node can provide data at the request of others, but also make requests and communicate with other nodes.
Why it is hard to deal peer-to-peer networks:
- implementation of the reliable P2P system is a complex task;
- configuration can be completely different from node to node;
- nodes can be online or offline at any given point of time;
- it is not possible to trust the message from other nodes (In client-server model you can trust server node at some degree);
- additional effort needed for communication and coordination of messages in the system;
Well-known P2P examples
As peer-to-peer technology has evolved, a lot of real-wolrd implementations have appeared.
There are several generations of Peer-to-Peer networks:
- First generation. Dedicated servers are still used as databases or node coordination servers. Examples: Napster, EDonkey2000.
- Second generation. There are no dedicated servers at all - all nodes are completely equal. Search and download protocols from other sites are not very effective. Example: Gnutella.
- Third generation. The network is completely decentralized. Data retrieval is performed more efficiently and quickly - using an algorithm that uses distributed hash tables. Example: BitTorrent.
Communication in a peer-to-peer networks
As we learn peer-to-peer networks more, one of the most fascinating questions may appear: “How do peer-to-peer nodes know about any updates or messages?”
If we are dealing with a centralized system, the issue is solved very simply.
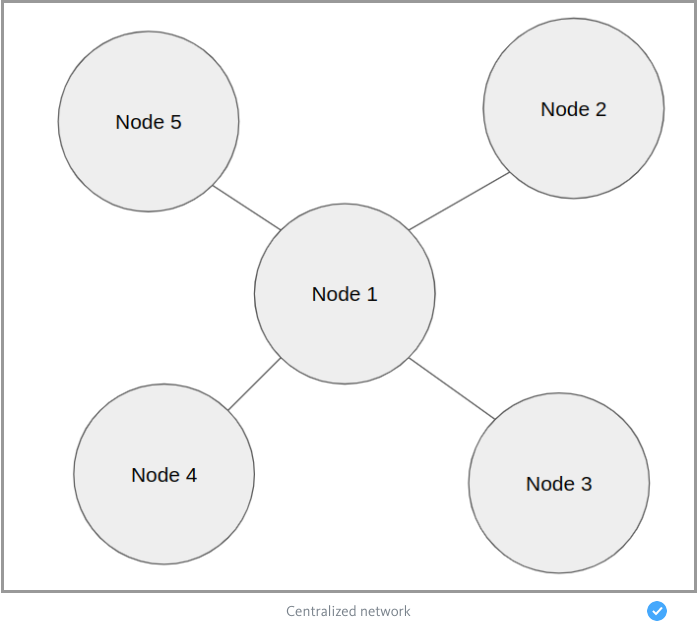
All nodes are connected to the server node (Node 1) and receive information from it about any state changes. It does not matter whether the nodes themselves poll the server, or the server distributes new messages themselves. But if the server node stops working for some reason, the system will no longer be able to receive new updates.
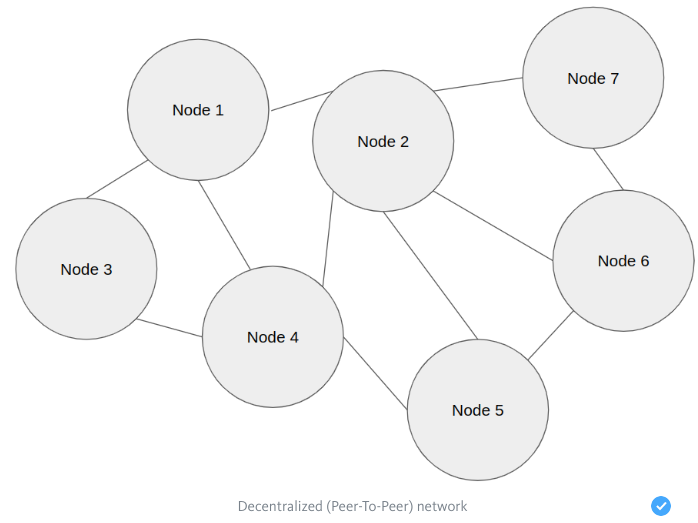
The task becomes more difficult when there is no dedicated node in the peer-to-peer system, which would be the “server” or “coordinator”. Each node is self-sufficient and equal. The only thing that can be done in such a system is to exchange messages.
The Gossip protocol helps to solve the problem when the network is decentralized and unreliable and when the nodes may also be unreliable.
How the Gossip protocol works
The Gossip protocol works in much the same way as gossip or epidemics spread in life. To do this, we use a simulator.
Imagine that we have a peer-to-peer decentralized network of 20 nodes. As soon as one node receives a new message - it must spread it to all other participants. For each node, we can choose fanout values - how many other nodes we can send messages to in one round. For example fanout = 4.
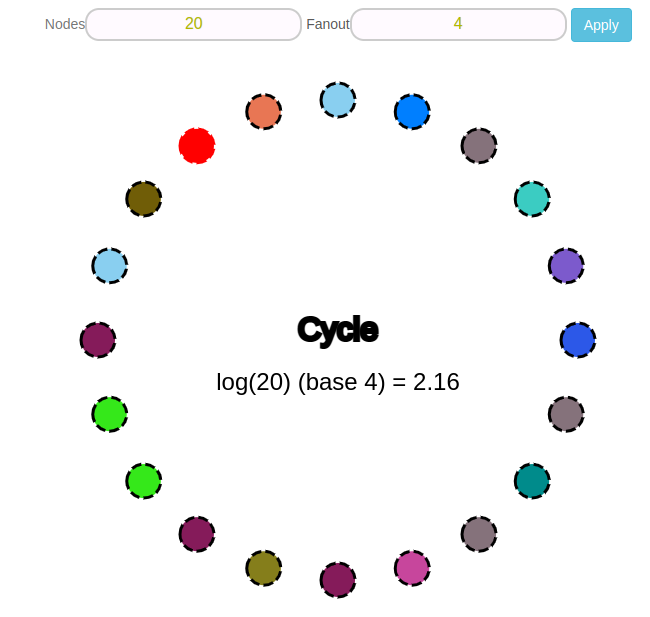
In each round, the receiving node sends it to the other four participants.
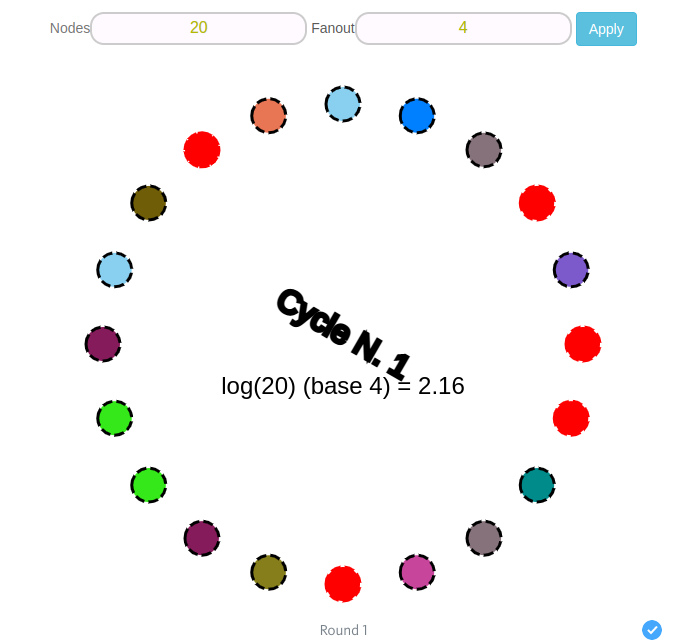
In the next round, each updated node sends message to other four randomly chosen nodes
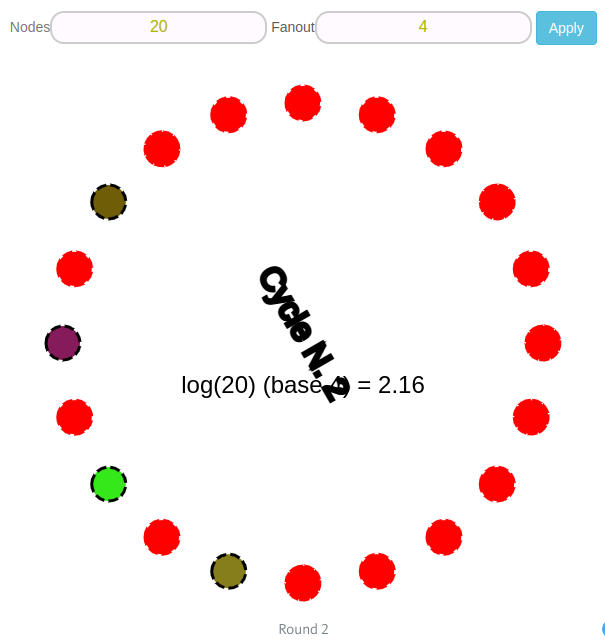
Yes, rounds are repeated until all nodes have a message.
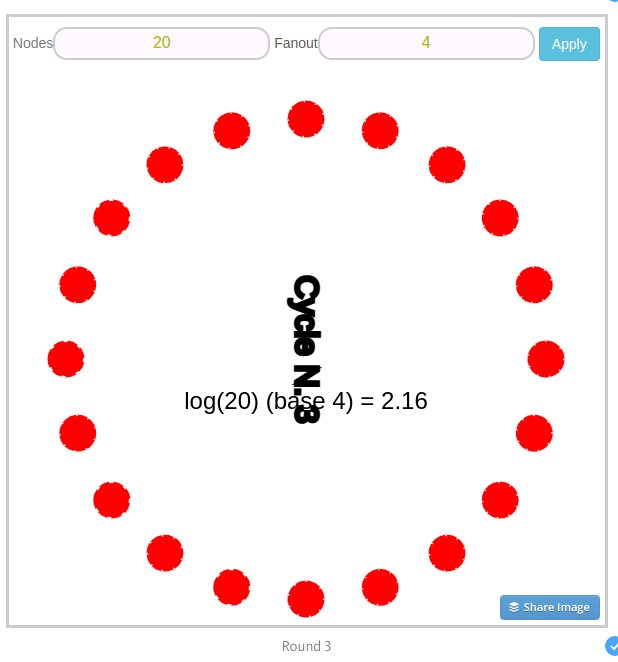
Theoretically, you can calculate how many rounds it takes for all nodes in the system to receive messages and be synchronized. The number of rounds depends on the number of nodes and the fanout value.

There are multiple ways how node can get information about new updates and messages:
- Push model - nodes with new updates send them to other nodes
- Pull model - nodes actively request updates from other nodes
- Push-pull model - nodes can request for new and send updates
Pros and cons of Gossip protocol
Advantages:
- Simplicity of the protocol
- High fault-tolerance
- High scalability O(logN)
Disadvantages:
- Slow work
- Delays (new messages are not processed until all rounds are over)
- Hard to debug
Conclusions
Peer-to-peer networks are not a “silver bullet”. They have pros and cons. That’s why client-server approach is a widespread right now. P2P networks can be useful in some cases - e.g. in the blockchain networks.
Although the Gossip protocol is quite simple and obvious, it has many applications in real systems. In the following posts, we will see in more detail how the Gossip protocol works on the example of Bitcoin and other blockchains.
For those who want to understand the work of the Gossip protocol in more detail and theoretically - I recommend an interesting scientific work on this topic.