Photo by Shubham Dhage on Unsplash
This is the fourth blog post in the “Blockchain for Test Engineers” series.
In the previous posts, we talked about the tiny little pieces of blockchain knowledge: hashing, encryption and digital signatures. This time we will examine bits of the vast topic of distributed systems.
Why would I need to know about distributed systems - I’m just a tester?
If you are testing an application that is little more than a couple of simple scripts, there is a non-zero chance that you are developing (or using) distributed systems in one way or another.
- Does your application have a database? It may be distributed.
- Do you have microservices on the backend? It is also, in essence, a distributed system. Do load balancers regulate the incoming traffic? Balancers can also be distributed.
- Components exchange messages via messaging (for example, Apache Kafka)? And that can be distributed too. Do you host several data centers in different parts of the world to give users faster answers? This is also a distributed system.
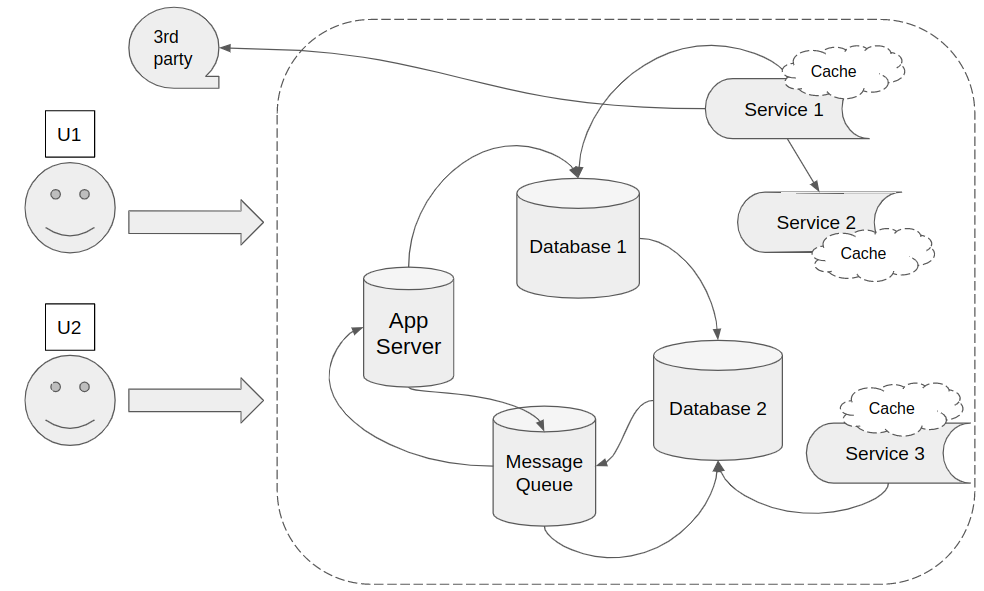
In fact, almost any large modern application is a distributed system. And consists of several smaller systems.
In my opinion, test engineers who deal with distributed systems in one way or another should at least know these three things:
- how do these systems work? (easy level)
- how can these systems fail? (medium level)
- how can the risk of failure be reduced? (hard level)
Also - almost each blockchain system is distributed and peer-to-peer in a nutshell. So you need to know how distributed systems work and on which principles they are built.
Why do we need distributed systems at all?
- Resiliency. If all calculations are carried out on only one machine, then the failure of such a machine will mean that the entire system will be inaccessible to the user.
- Performance. Even the most powerful one, no single computer can handle simultaneous requests from millions and billions of users.
- Handle significant computational problems. Many tasks will be impossible or highly time-consuming to compute on a single machine.
What is a Distributed System?
In simple words, a distributed system is a system that consists of many nodes (for example, computers, processes, devices) that communicate over a network and perform some form of a task together.
Leslie Lamport, a renowned researcher and author of scientific papers, gave this description: ”. . . a system in which the failure of a computer you didn’t even know existed can render your own computer unusable.”
Distributed systems are a really vast topic. A lot of researchers dedicate their lives to learning distributed systems.
As an engineer, you need to be aware of the following things about distributed systems:
- what are timing models (synchronous, asynchronous, or partially synchronous)
- what is the type of communication between nodes
- what are failure modes (the node can stop working in case of failure or recover automatically)
- what are failure detectors in the system (how nodes can discover that something wrong happened to other nodes)
- what are leader elections, quorums, and consensus protocols mean (RAFT, Paxos, Multi-Paxos, etc.)
- how to calculate time in distributed systems (primarily if the nodes are geographically distributed around the world)
- what are the standard whitepapers and principles in distributed systems (e.g., FLP Consensus)
What are the misconceptions about distributed systems?
Developers who write code for distributed systems are far from ideal. Especially if they are new to the industry or have never dealt with massive systems. Such developers can form many false assumptions about distributed systems in their heads.
Peter Deutsch (and several other engineers) from Sun Microsystems back in the 90s formed a list of these assumptions. It can be found as “8 fallacies of distributed computing” on the Internet.
Eight misconceptions about distributed systems:
- The network is reliable. In reality, packets in the network can be lost; services can stop and endlessly wait for a response.
- Network latency is zero. There will always be network latency - at least, it’s limited by the speed of light. It is impossible to instantly transmit a packet over the network from one point on the Earth to another.
- The bandwidth is infinite. The bandwidth is limited, but it can also be different for different nodes.
- The network is secure. In fact, any messages sent over the network can be intercepted by attackers. Or hosts can be attacked or blocked.
- The network topology does not change.
- There is always one administrator on the network. Nodes and subnets can be managed by many various companies with different security policies.
- Transport costs are zero.
- The network is homogeneous. In the real world, nodes on a network can be completely different, with different characteristics.
Distributed systems from a testing point of view
As distributed systems have many aspects, let’s take one of them as an example: communication.
By communication, we mean exchanging messages between two nodes (Node 1 and Node 2) or between the client and any node in the system. The most straightforward and practical example is when a client makes a standard HTTP request to a server.
What can happen in communication between two nodes?
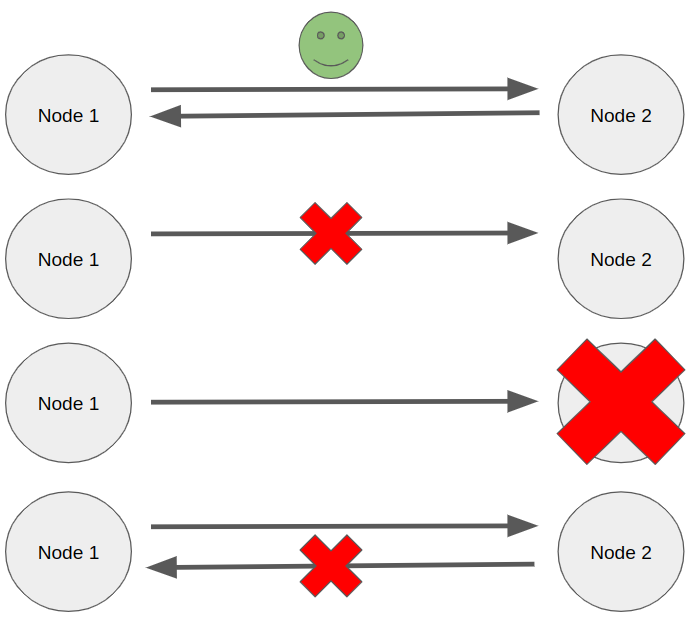
- Node 1 sends a request and receives a response from Node 2.
- Node 1 sends a request, and the request will not reach Node 2.
- Node 1 sends a request, and Node 2 receives the request and tries to process it. During processing, Node 2 becomes unavailable for Node 1. (But under the hood, Node 2 can also make requests to other nodes!)
- Node 1 sends a request to Node 2. Node 2 processes the request and returns a response, but Node 1 does not receive it.
If Node 1 does not receive a response from Node 2, then it will not be able to understand what is causing the problem. It could be network problems and message loss, a Node 2 problem, or a dead link.
So that Node 1 does not wait forever for a response, you can use the mechanism of waiting (Timeout) for a response. Out of timeout - Node 1 generated a communication error.
But what should be the timeout?
If you set the timeout too low, Node 1 may mistakenly think that Node 2 is unavailable. On the other hand, if the timeout is too long, the waiting time can significantly impact system performance.
You can use the ping and heartbeat mechanisms as an alternative to timeouts.
- Ping. Node 1 can ping Node 2 from time to time and check if the node is alive. Even if, at some point, the node does not respond, Node 1 can continue to send such requests in the hope that Node 2 will be available sooner or later.
- Heartbeat. Node 2 can send particular messages to all nodes it communicates. Thus, it notifies the network that it is up and running. If Node 1 does not receive heartbeat messages from Node 2, it marks that node as unreachable.
Both mechanisms are used in distributed systems - e.g., for communication and synchronizing microservices on the backend.
It is only one example of how we can think about distributed systems and try to develop testing scenarios for them.
Learning about distributed systems
It is up to you to dive into distributed systems in-depth or not. Suppose you test some DeFi protocols or applications that only use a specific blockchain (Ethereum or Cardano). In that case, you need to concentrate on these protocols’ technical and business aspects first. Learning about internals adds more benefits later.
But if you are a part of a core development team or building a distributed system (or blockchain) from scratch - you must know the theoretical basis.
If you are interested in distributed systems - I want to share a few resources on where to start.
- Simple explanations can be found in the introductory course created by Chris Colohan. It is a good starting point for newcomers.
- If you want to read a single book - it is “Designing Data-Intensive Applications” by Martin Kleppmann. I even made a review post about this book last year.. The book can be hard to read, but it is full of helpful information.
-
If you prefer to watch videos - here is a course on distributed systems at the University of Cambridge taught by Martin Kleppmann
What can you learn from the course?
- what distributed systems are and how nodes can communicate with each other
- canonical theoretical tasks from two generals to Byzantine ones.
- time and how to work with it in large systems: physical and logical clocks, clock synchronization, and cause-and-effect relationship of events on different nodes
- the concept of replication and quorums, as well as message broadcasting algorithms
- consensus algorithms - from the simplest to even simpler (RAFT)
- how Google Spanner works and different tools for collaboration between users
- For more in-depth explanations of consensus protocols you can watch an academic course from Lindsey Kooper
Conclusions
Distributed systems are a vast but really fascinating topic to learn. As our modern systems are getting bigger and more complex, the knowledge about distributed computing and consensus algorithms can significantly benefit you.
It is a must-have knowledge if you work with blockchain systems (at least from the theoretical part). Otherwise, you will always test your app against the blockchain as a black-box.
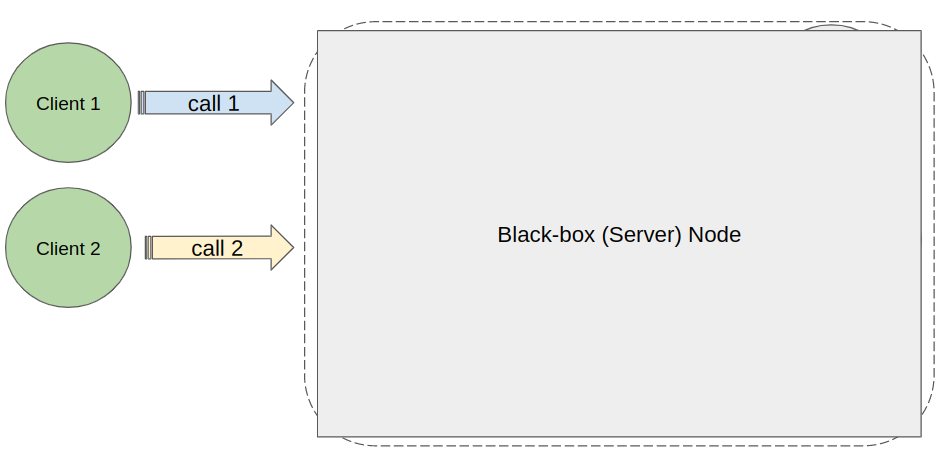
Such testing is not a bad thing at all - but you may miss a lot of important internal issues by concentrating only on the surface.